
The importance of structured data, a type of code that makes the content of webpages easier for search engines to interpret, is frequently emphasised in advice articles and presentations about SEO.
We’re told that structured data can help make your webpage more visible in the SERPs; that it can help you get rich results and featured snippets; that it’s important for voice search.
Yet although the benefits of structured data are widely agreed upon, there is a noticeable lack of concrete figures that SEOs can point to when making the case for structured data. Where are all the structured data studies, case studies and statistics?
At Brighton SEO on Friday, Kenichi Suzuki – Search Advocate at Faber Company Inc. and Japan’s “most famous SEO blogger” – significantly added to the body of information on structured data with an excellent talk rounding up four case studies that show how using structured data can benefit SEO.
Suzuki also showed two examples of new types of rich results, How To and FAQ, that are still in the testing phase, which may well become case studies once these rich result types are officially deployed.
PLOS: Dataset search
Last September, Google launched a new vertical search engine called Dataset Search. Still in beta at the time of writing, Dataset Search is a search engine that indexes free-to-use online data to make it easier for researchers, scientists and data journalists to discover datasets.
In order to be indexed by the search engine, institutions that publish their data online need to use structured data or schema.org markup – a type of structured data vocabulary developed collaboratively by Google, Microsoft, Yahoo and Yandex – to label elements such as the date published, who created the data, how it was collected, and so on.
For organisations that publish data, the benefits from a discovery standpoint are considerable. Figshare, an online open-access repository of research and datasets, tweeted about the “immediate impact” that Google Dataset Search had had on traffic to PLOS, an open-access publisher of scientific research.
PLOS saw its organic traffic almost double after being indexed by Dataset Search (when compared with figures from the week before), with more than 8,100 pageviews coming directly from Dataset Search (labelled in the table below as toolbox.google.com).
Google Dataset Search having an immediate impact on the discoverability of data supporting published academic articles – Here’s the first few days for @PLOS pic.twitter.com/bWLCQG0Jyk
— figshare (@figshare) September 10, 2018
jobrapido: Job Posting structured data
In 2017, Google launched a new feature called ‘Google for Jobs’ at Google I/O, designed to make job postings appear more prominently in search.
Shortly afterwards, it announced a new type of schema.org markup called Job Posting that sitemasters and SEOs could add to give themselves a chance of getting enriched job search results.
Jobrapido, a major jobs search platform, started using Job Posting schema markup in order to increase its visibility in search and attract “more motivated applicants”. Jean-Pierre Rabbath, VP of Product at Jobrapido, wrote on Google Developers that, “Jobrapido has always been one of the first companies to adopt Google’s new services with the goal to constantly improve the user experience.”
Following the launch of Google for Jobs, Jobrapido observed a 270% increase in new user registrations from organic traffic. Organic traffic to Jobrapido also increased by 115% in multiple countries: Spain, Nigeria, and South Africa.
Notably, the overall bounce rate on Jobrapido also went down by 15%, which indicates that searchers were navigating to the site and browsing around, not just clicking on a job listing and then leaving the site directly afterwards.
Brainly: QA Page structured data
The third case study Suzuki cited was Brainly, a question and answer forum for students. Brainly was an early implementer of a new type of structured data for question and answer pages called QAPage that Google began testing in mid-2018, and officially announced in December 2018.
Shortly after Google’s announcement of the feature, Murat Yatagan, Brainly’s VP of Growth, announced that implementing QAPage structured data had boosted the average click-through rate on QA pages that were featured in search by 15-25%. As one of the drawbacks often cited about Google’s rich results is that they satisfy user search queries on the SERP, thereby reducing click-through to a business’s website, these results are particularly encouraging.
Exciting news for QA websites. At @brainly we have deployed QAPage SD markups on all our markets a while ago, and the results are very positive: average CTR of QAPage search appearance is 15-25% higher than the average CTR of total knowledge base https://t.co/gTMq5YZ60P
— Murat Yatagan (@muratyatagan) December 5, 2018
Rakuten: Recipe rich results
Rakuten is one of the largest IT companies in Japan and boasts a wide range of services and websites including fintech, ecommerce and loyalty programs. It also produces Rakuten Recipes, one of Japan’s most popular recipe websites.
Rakuten Recipes was launched in 2010, and began using structured data just two years later, in 2012 – making it a fairly early adopter of structured data markup. In 2014, Rakuten expanded its usage of structured data to help surface the exact type of recipe content that users might be looking for, and in 2017, collaborated with Google to improve its structured data even further.
Rakuten was already using Accelerated Mobile Pages (AMP), which when combined with structured data, help websites to gain rich results in mobile search. The company then used Google’s Search Console to identify areas where it could provide more information to take full advantage of rich results like Recipe Cards, and also used Google’s Structured Data Testing Tool to identify any errors in its markup.
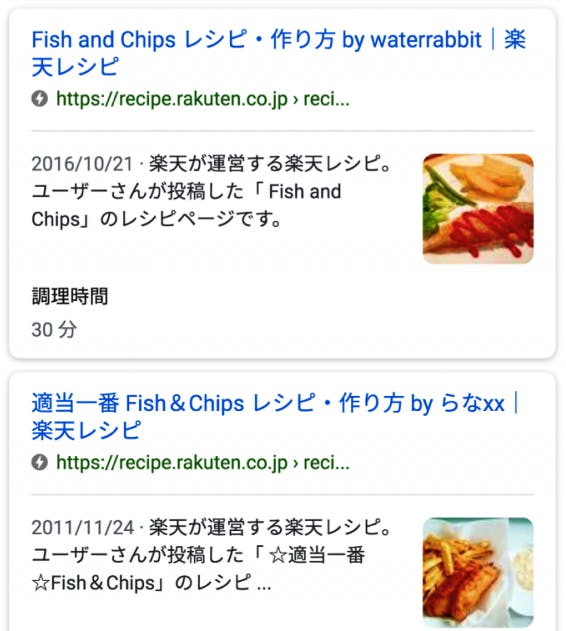
Image by Kenichi Suzuki
In a Google Developers write-up of the case study, Rakuten Recipe group manager Yuki Uchida reports that Rakuten opted to make all of its recipes available as rich recipe cards on the same day that the Rich Cards report was released in Google Search Console – “full on at the first release”.
The returns quickly began to show: traffic to all Rakuten Recipe pages from Google search saw a 270% increase, and the average session duration on Rakuten’s site also increased 150%. Uchida said that the inclusion of Recipe Cards in search had helped users “match with more recipes, and spend more time enjoying and cooking the recipes we have.”
To be launched: How To and FAQ
In July 2018 at Google Dance Singapore, a Google-hosted meetup for website owners, webmasters and web developers, Google confirmed that it was testing three new types of rich result: QA, FAQ, and How To. QA, as we’ve already seen, was officially rolled out in December, while the other two rich result types are still in the testing phase.
Suzuki showed the audience at Brighton SEO what these types of rich result look like in action. How To rich results are being trialled by team collaboration software company Slack and appear in mobile search results as drop-down headers similar to the ‘People Also Ask’ feature: when a header is selected, that step of the instructions is revealed beneath it.
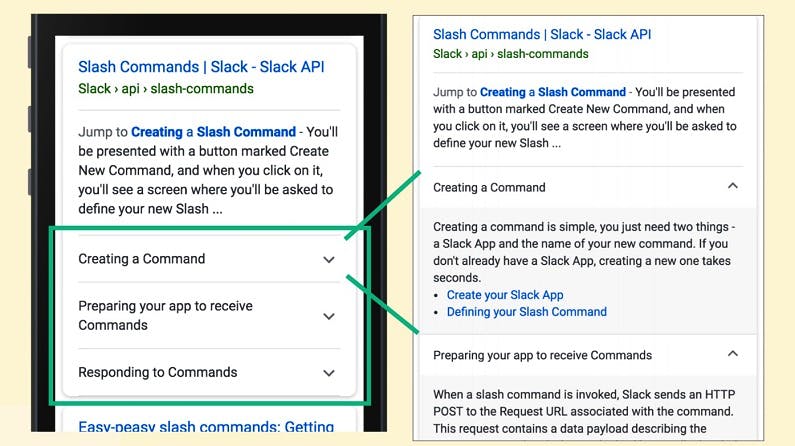
Image by Kenichi Suzuki
Google’s FAQ rich result appears in a very similar format but is designed for FAQ pages (these differ from QA pages in that they have multiple questions and answers, whereas QA pages only have one).
FAQ rich results show each question from a FAQ as a dropdown, which reveals the answer when it is selected. The feature is currently being trialled by Japanese food and beverage brand Suntory.

Image by Kenichi Suzuki
It will be particularly interesting to see how these new types of rich results perform once they are rolled out fully, as both place a heavy emphasis on users reading content on the search results page – but may also entice them to click through to the website in question to read the full tutorial or FAQ.
Learn more
Subscribers can download Econsultancy’s SEO Best Practice Guide or read online.