

Like any SEO veteran, I can recount my share of horror stories — launching Google Analytics and noticing that sudden, sickening drop in traffic.
Sometimes, sudden drops in traffic may be the result of an algorithm changes (such as Panda). However, in many cases, they are caused by bugs, inadvertent changes or overambitious engineers with a little bit of SEO knowledge.
In this article, I will examine three real-life case studies and outline the steps necessary for SEO disaster prevention.
Case #1: “Something Bad Is Happening To My Website.â€
I was at a company offsite, and my phone had been vibrating with several calls. I left my meeting and saw that my good friend (let’s call him “Tonyâ€) had called several times and left a message: “I think something bad happening to my website. Traffic is crashing. Some sort of SEO problem.â€
Tony runs iFly, an extremely successful airport information site. Like many of us, he is very dependent on Google traffic; an SEO issue would be a big problem, indeed.
To give you an idea of how bad “something bad†was, look at this drop:
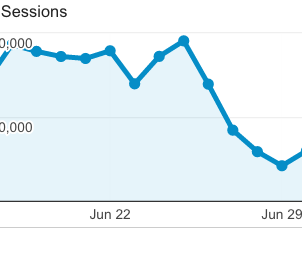
Murphy’s Law: “Anything that can go wrong will go wrong.
“You found what on my site?â€
When I first got the call from Tony, I suspected Panda because an update to the algorithm had just been released. Fortunately for Tony and iFly, it was not a Panda event.
The first thing I noticed was that the traffic drop impacted organic search traffic from both Google and Bing. That was great news, as it implied a technical problem. I took a look at the source, and lo and behold:
meta name=â€robots†content=â€noindex“
In the iFly case, there was a tiny bug that resulted in the meta tag above being inserted into every page in the site. This one line of code was the cause of all his troubles. Essentially, it told Google and Bing to ignore every page of his site. They obliged.
Case #2: “Our Traffic Seems Soft.â€
Early in my career, I ran product management for a site called RealTravel. You won’t find it online anymore — it was sold to Groupon and eventually shut down.
One morning, I arrived at work and got ready for my usual daily kickoff of coffee and Google Analytics. Our CEO came over with a worried look on his face.
“Our traffic seems kind of soft, can you see what’s going on?†We had been on a traffic upswing.
I generally open my Google Analytics reports with optimistic anticipation. That day, though, I had a sense of dread. Sure enough, we were down about 20 percentage points. It was a kick right in the gut.
The next day, we dropped a bit more, and then even more. Within a couple of weeks, we were down about 30 percent. This was a time when we needed to show traffic and go for funding. It’s hard to get funding when your traffic does this:
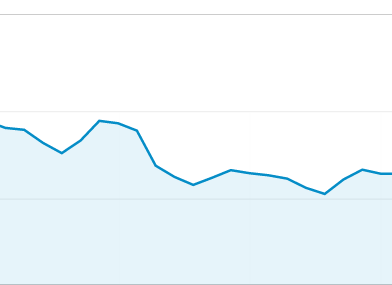
Smith’s Law: “Murphy was an optimist.â€
Over the next week or so, I scoured our site, our rankings, Webmaster Tools, and our backlink reports to try to figure out what was going on.
I couldn’t initially imagine that it was related to changes we’d made a year earlier when we had gone through a site re-architecture. We had handled things correctly. We’d put in 301 redirects as Google recommends, mapping the old content to the new content. Things had gone swimmingly after the relaunch. In fact, traffic had shown a steady increase. A year later, I was not considering the site architecture as the potential cause. So naive…
A couple of weeks into the problem, I noticed that some old URLs were giving 404 errors in Google Webmaster Tools.
I started checking more of the old URLs and saw that many of them were 404-ing. My engineer looked into it and told me, apologetically, that he had made a configuration change that broke the redirects. Yikes! We had lost the value of all our historic deep links, and our domain authority had suffered.
Traffic eventually came back, but it was serious damage to a struggling startup.
Broken redirects: a nasty problem
There are lots of very valid reasons to change URLs. In our case, the new site architecture required it. Other reasons include:
- Including the primary keyword in the URL.
- Removing URL parameters.
- Creating user-friendly URLs.
- Changing the folder structure.
- Moving to a new domain.
- Switching to HTTPS (yes, those are different URLs).
- Normalizing on a domain name with or without “www.â€
While the way to handle redirects is well known (the use of 301 redirects) and most SEOs will get them set up correctly, their usage creates a dangerous vulnerability if you have strong external links going into the old URLs. It hit RealTravel severely.
Any problems immediately after the change are quite obvious. Google would still have the old URLs in the index, and clicking on the results would lead to 404s, so you would see no traffic coming into the new pages.
However, when it happens well after the fact, it is a particularly insidious problem. The site still works fine. Google’s index contains the new URLs, so click-throughs from the SERP work fine. You might notice a traffic drop in referral traffic, but for most sites, that is insignificant. You only notice a problem if you happen to click on a link from an external site.
Eventually, you will see the 404s in the Google Search Console crawl error report. However, there is a lag there, and by the time you notice these 404s, a good deal of the damage may have been done. Worst of all, if it’s only a few high-value URLs, you might not even notice.
I learned my lesson. Now, any time I do a URL change or site move since, I insist on monitoring the redirects with test scripts, forever. Very, very few sites have a policy like this.
Case #3: “We Think Bing Has Hurt Our Google SEO.â€Â
I joined a large consumer top 100 US website to manage the SEO team. This is one of the most visible sites on the Web, one that you would surely know.
After years of hockey-stick growth, they had a sudden flattening of traffic over the previous six months. The director of product management told me something had been wrong with SEO.
They were pretty sure they’d identified the problem and believed that Bing was the cause. Bing had started crawling the site at an incredible pace, which had bogged down the servers (they had dedicated servers for the crawlers). In their estimation, the server response time had degraded such that Google was crawling fewer pages.
It was a good theory, and they had pretty much settled on it. Still, even after they had resolved this issue, traffic had not bounced back. The idea of  blaming Bing for a Google problem was a good story. I found the irony quite amusing.
I wasn’t quite buying it. This was not definitive enough for me. I wanted to dig in, so I did.
Like many development teams these days, they had an agile website, with bi-weekly releases and frequent patches. I asked for a history of changes so I could get a handle on potential causes for the traffic drop. I was provided a bunch of cryptic engineering release notes from three or four of the website updates over that six-month period.  Lots of stuff had changed, but nobody knew what, beyond a couple of major features.
I can’t show actual traffic numbers, but SimilarWeb highlights when the apparent problem surfaced.
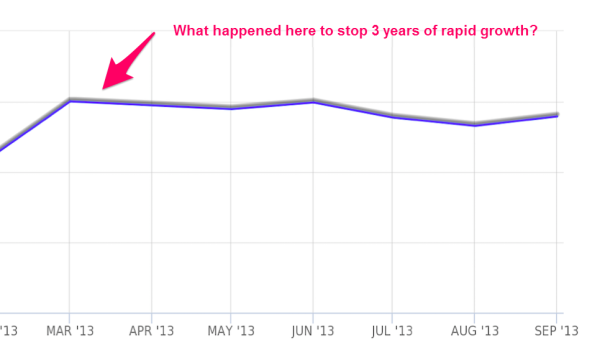
Munroe’s Law: “With SEO, whatever can break, will break. Whatever can’t possibly break will also break.â€
The Missing Links
This one was tricky to detect. They had actually introduced a bug six months earlier that was obscure and far from obvious.
The site was dependent on long-tail traffic from a specific type of content that was only crawlable via a deep HTML sitemap. The bug removed about half the content from these sitemaps. This issue went undetected for so long because HTML sitemaps are rarely visited pages.
Even so, the pages were not broken. The only way to detect his problem would have been to audit the links on these pages vs. the content that should be generated on those pages (which is how I detected the problem).
More GotchasÂ
With the increasing technical complexity of websites and SEO, there is a huge list of potential issues which can affect traffic and rankings. At SEORadar (my company), some of the issues we have come across include:
- Rel=canonicals. A common problem is broken or accidental removal of the rel=â€canonical†link element, which specifies the canonical page among those which have duplicate content. Rel=canonical problems abound, as many pages have logic to determine whether to put on a self-referential rel=canonical or legitimately point to another URL.
- Nofollow links. We’ve come across sites with “nofollow†link tags for all the links on a home page. In one case, all the paginated links on a blog were nofollowed, preventing multi-paged posts from getting link equity.
- Meta Robots. We’ve seen the nofollow, as well as the noindex meta tags, on pages where they did not belong. We’ve also seen noindex removed inadvertently, which led to Google’s index getting flooded with low-quality pages.
- Robots.txt. Sometimes, websites inadvertently configure their robots.txt file to block pages and or resources (blocking CSS can be a major mobile SEO issue).
- 301 redirects. The most common 301 redirect issues involve accidentally removing redirects or morphing 301s into 302s.
- Page titles. We’ve seen these getting accidentally wiped out or set to the domain name.
- H1 tags. Issues often arise when h1 tags lose keywords and/or get deleted from the page.
- AJAX sites. Sometimes, websites using AJAX serve the wrong content to the search engine spiders. (This is particularly nasty, since spiders get their own distinct version of the page, and you need to regularly look at what the spider is getting served.)
- Hreflang. The hreflang tag, which allows you to specify which version of a page should be served based on the user’s language or region, sometimes gets deleted.
- Footer and Navigation links. Problems arise when links to important content are deleted.
- Cross-links. Cross-link to important content might be removed, diminishing that content’s authority.
- Meta Descriptions. Issues arise when the same meta description is posted to every page on the site or getting deleted.
Reality Is Stranger Than Fiction
Some cases are so strange that you would have trouble believing it:
- Imagine a site that has built a nice, friendly m.dot implementation. However, the mobile crawler was not seeing this site. Apparently, there was some old cloaking code that served up the old “dumb†phone/feature phone version of the site to the spiders. Yes, they went to the trouble of building a great mobile site and hid it from the spiders.
- Another site, a software service, had an opt-out page to cancel their service. Somehow, an entire content section of the site had rel=â€canonical†links pointing back to the opt-out page (ironically strengthening the one page on the site they did not want users to actually see).
- On one site we looked at, there was some cloaking logic serving bad rel=canonicals to the crawler. If you looked at the page source from your browser, the rel=canonicals looked fine. To catch this, you had to compare the rel=canonicals in Google’s cache to what was on the user’s page.
You can’t make this stuff up!
Why Do So Many Things Break?
How can these things possibly happen?
- Complexity and “if†statements. Consider the meta robots “noindex†tag:
- Some content you may want indexed, and some you may not. In that case, there is often logic that is executed to determine whether or not to insert the “noindex†tag. Any time there is logic and “if†statements, you run a risk of a bug.
- Typically, sites have staging environments or subdomains they don’t want to be indexed. In this case, logic is needed to detect the environment — another opportunity for a bug if that logic gets pushed live.
- Sometimes, developers copy templates to build a new page. That old template may have had a noindex.
- Frequent releases. Most websites have at least weekly updates, as well as patch releases. Every update presents a risk.
- CMS updates. Manual updates to content via CMS can completely de-optimize a page. For sites that use WordPress, it is very easy to accidentally noindex a page if you use the Yoast plugin. In fact, I know one very prominent site that noindexed their most visited blog post.
- Competing interests. Many hands with competing interests all have the potential to muck up your SEO. Whether it’s designers deleting some important text, product managers deleting navigation, or engineers using AJAX and hiding important content, the risk is ever-present that something can go wrong.
What Happened To My Site?
Most websites do not have a good handle on what updates and changes have been made to their website (and when). Sure, there might be some well-written release notes (although cryptic seems more common), but that won’t tell you exactly what changed on a page.
How can you research a traffic drop if you don’t know what has changed? The current modus operandi is to go to the Internet Archive and hope they have a version of the page you are interested in.
This is not just an SEO issue. It impacts conversion, monetization, UX metrics — in fact, all website KPIs. How can you understand what’s causing a shift in your KPIs if you don’t know exactly what changed and when?
SEO Testing
SEO testing is also a big problem.
Let’s say there are 10 important page templates for a site and 20 things you want to verify on each page template. That’s 200 verifications you must do with every release.
These tests are not black and white.  The existing of a no-index tag on a page is not necessarily a problem. Just because a page has a title, doesn’t mean it has the right title and it hasn’t changed.  Just because there is a rel canonical, doesn’t mean it is linking to the right destination.  It’s easy to write a test script to tell you that a title is missing.  It is difficult to tell the title has had it’s keywords removed.
Gaining Control
Murphy’s First Corollary: “Left to themselves, things tend to go from bad to worse.â€Â
… so they can’t be left to themselves.
I’ve painted a pretty scary picture here. SEO is fragile. I am sure many sites have lost traffic with no clue that they are the victims of a preventable problem.
Every SEO needs to have tools and processes in place to prevent these mishaps, and implement education programs, so that every part of an enterprise (large or small) understands what can impact SEO.
Audit
You can use an audit to get a good baseline of your site. While it won’t tell you whether a title has been changed and important keywords lost, you can use it to make sure there are no problems with the current state of the site.
All the major enterprise platforms provide some audit capabilities, and you can supplement this with tools like Moz, Raven and Screaming Frog.
If you have a good handle of the current state of your site, then life becomes easier; you can focus on looking at changes when new releases are pushed. However, an audit is just the starting point.
Change Monitoring
Whenever a new version of your site is pushed live — or better yet, is still in staging — the most critical thing to do is a change analysis.
If you know (from your audit) that the site was in a good state before the push, then just looking for changes will minimize your work. You only need to take a close look at things that have changed to validate that nothing has broken.
It’s best to use something that monitors and alerts you to change and potential problems. For that, I recommend:
- SEORadar (disclaimer: this is the company I founded). It is focused explicitly on monitoring changes and generating alerts. You can get a fair amount of protection with the free version, which includes redirect monitoring if you have changed URLs.
- RioSEO. This is the only other extensive change monitoring system focused on SEO that I know of.  It’s contained within their enterprise platform.
- In-house developed tools and scripts. Some companies prefer to develop their own test and monitoring solutions.
- Robotto. Somewhat limited, but still useful. It monitors for robots.txt changes and basic HTTP redirect tests.
- Manual process. If you maintain a regular archive of your pages, you can set up a manual process. You will need this to analyze changes, and this will be invaluable if you need to troubleshoot SEO or other site issues. For instance, you can do this by saving audits run with Screaming Frog.
- The Internet Archive. This is another possibility for an archive; however, it is hit or miss on whether it will have the page you are looking for.
What Pages Should You Monitor?
- Page templates or page types that generate significant traffic. For instance, on an e-commerce site, that would include product pages, category pages and brand pages. Generally, these pages are generated algorithmically off of the same page template, so monitoring a few instances of each page type should suffice.
- Pages that are important for indexing (HTML sitemaps, indexes and other pages that play a major role in getting content indexed, even if they don’t generate much traffic.
- The home page.
- Individual content pieces or blog posts that generate significant traffic or are otherwise important strategically.
Links, Links… Precious Links
Links are more precious than ever in 2015. Imagine that a simple, hard-to-detect server configuration issue could negate the value of many of your deep links (and all that PR and branding you did to get those links)?
Don’t let a server configuration problem damage your domain authority, as in the case of RealTravel. If you have changed your URLs (or even switched to HTTPS), you want to know that those redirects are always in place. You need to monitor those links forever and ever. Either write custom scripts or use an app/software that monitors your old URLs.
Education
With SEO, you will be in a state of perpetual education and training. You want everyone on your team protecting and preserving your website’s SEO. They have to know the risks and potential consequences of various changes to the site.
To achieve that, you need to focus on education by doing the following:
- Periodic training with  product managers, engineers and quality assurance.
- Push as much testing as possible over to QA. Provide them with a checklist for their verification process. However, do not depend on it. If something breaks, all eyes will be on SEO.
- While company-wide training is good, individual training with each team is important, as well. It is more personalized and helps get buy-in and commitment.
- Provide backup material and cheat sheets describing all the on-page elements of importance.
- Over-communicate whenever some sort of SEO discussion comes up. Always explain the “why.†What is second nature to you is going to be very slow to register with people who are not involved with SEO. People just won’t get it from sitting through a single PowerPoint presentation — it takes repetition.
Process
SEOs shouldn’t fully depend on other teams to maintain a website’s SEO. We must be proactive, as well, by developing a process for monitoring and identifying site changes, and we must make this process a habit.
- Know what changes are being made to your website. Attend product meetings.
- Have a review with your QA team to quickly highlight potential problem areas in each new release to help them understand where they should focus.
- Repeat SEO training sessions on a regular schedule. Make sure new employees get indoctrinated.
- Test the site before a release goes out.
- Test again after the release goes out.
Control The ControllableÂ
Search engine optimization, particularly in-house SEO, is incredibly stressful. We have to control the uncontrollable and predict the unpredictable.
Let’s make things a bit easier by controlling the controllable and avoiding those SEO disasters. If you have any additional cautionary tales, please share.
Some opinions expressed in this article may be those of a guest author and not necessarily Search Engine Land. Staff authors are listed here.